World’s largest virtual agentic engineering & quality conference


- TestMu AI (Formerly LambdaTest)
- /
- Blog
- /
- Voice Quality Testing: Complete Guide for VoIP and AI Voice Agents (2026)
Voice Quality Testing: Complete Guide for VoIP and AI Voice Agents (2026)
The complete guide to voice quality testing in 2026. Covers MOS, PESQ, POLQA, WER, TTFA, AI voice agent testing with TestMu AI, and CI/CD integration for production voice systems.

Saniya Gazala
Author
Last Updated on: June 19, 2026
Voice quality testing used to mean one thing: checking whether a phone call sounded good. In 2026, it means something considerably more complex. You are now responsible for testing not just the network path a call travels, but the voice AI pipeline that decides what the voice on the other end actually says, how fast it responds, and whether it understands you at all.
The QA engineer checking a VoIP contact center and the SDET validating an AI-powered customer support voice bot are both doing voice quality testing. They use different metrics, different tools, and different failure definitions, but they share the same goal: making sure the voice experience does not break.
Both disciplines share a keyword but demand entirely different tooling, metrics, and failure definitions. The sections below cover foundational metrics and testing methods for any voice system, the additional testing layer that AI voice agent require, and how an agentic platform like TestMu AI fits into a production-grade voice quality testing workflow.
Overview
What Does Voice Quality Testing Actually Cover?
It is the practice of measuring and confirming the audio experience users receive across every voice-based system, from VoIP networks and IVR menus to contact centers and AI voice agents. The aim is to surface degradation and failures before customers ever hear them. Traditional work splits into three approaches, and for AI systems a fourth, behavioral layer is added to judge whether the agent understood the caller and finished the task.
Why Has Voice Quality Testing Become Critical in 2026?
- Infrastructure at scale: Enterprise VoIP and contact centers process enormous call volumes, where weak audio drives down satisfaction, raises abandonment, breaches SLAs, and shuts out voice-dependent users.
- Rapid AI agent rollout: Gartner expects 40% of enterprise applications to ship task-specific AI agents by the close of 2026, up from under 5% in 2025, and broken transcription or sluggish responses push callers straight to escalation.
- Compounding error rates: Because speech-to-text, language understanding, and text-to-speech multiply rather than average, 90% accuracy at each stage yields only ~73% end-to-end success, and 85% drags it down to ~61%.
- Always-on testing: Quality checks can no longer be occasional; modern voice systems need automated validation wired directly into release and production pipelines.
How Do You Test Voice Quality Step by Step?
- For VoIP and IVR: Map each call segment, prepare a realistic reference recording, inject and capture audio for PESQ or POLQA scoring, lock in a baseline for MOS, jitter, latency, and packet loss, then stress the path under degraded and peak load while scheduling synthetic calls for ongoing monitoring.
- For AI voice agents: Assemble a scenario library spanning happy paths, edge cases, error handling, adversarial inputs, and acoustic variation, instrument per-component latency, WER, intent accuracy, and task success, run a full pre-launch simulation in staging, gate releases through CI/CD regression checks, and watch production calls at P50, P95, and P99.
Where Do Voice Agent Testing Platforms Fit In?
TestMu AI (formerly LambdaTest) offers an AI-native agent testing platform built to validate voice agents through automated, multi-turn conversations across voice and chat. As teams adopt a growing stack of agentic AI tools, a simulated caller adapts its replies in real time rather than replaying fixed scripts, exposing failure modes like lost context, mishandled corrections, and broken escalations that scripted tools miss. It stays telephony-provider agnostic, drives tests through the testmu-a2a CLI, and scores each call across dimensions such as conversation flow, accuracy, user experience, operational metrics, audio quality, and speech-to-text reliability.
What Is Voice Quality Testing?
Voice quality testing measures and validates the audio experience users receive across VoIP networks, IVR platforms, contact centers, and AI voice agents, before failures reach real callers.
The goal is to catch degradation, errors, and failures before they reach real users. The field divides into three classical approaches and, for AI systems, a fourth evaluation layer.
The Three Classical Approaches
The evolution of voice quality assessment can be understood through three classical approaches, each balancing accuracy, scalability, and real-time applicability differently.
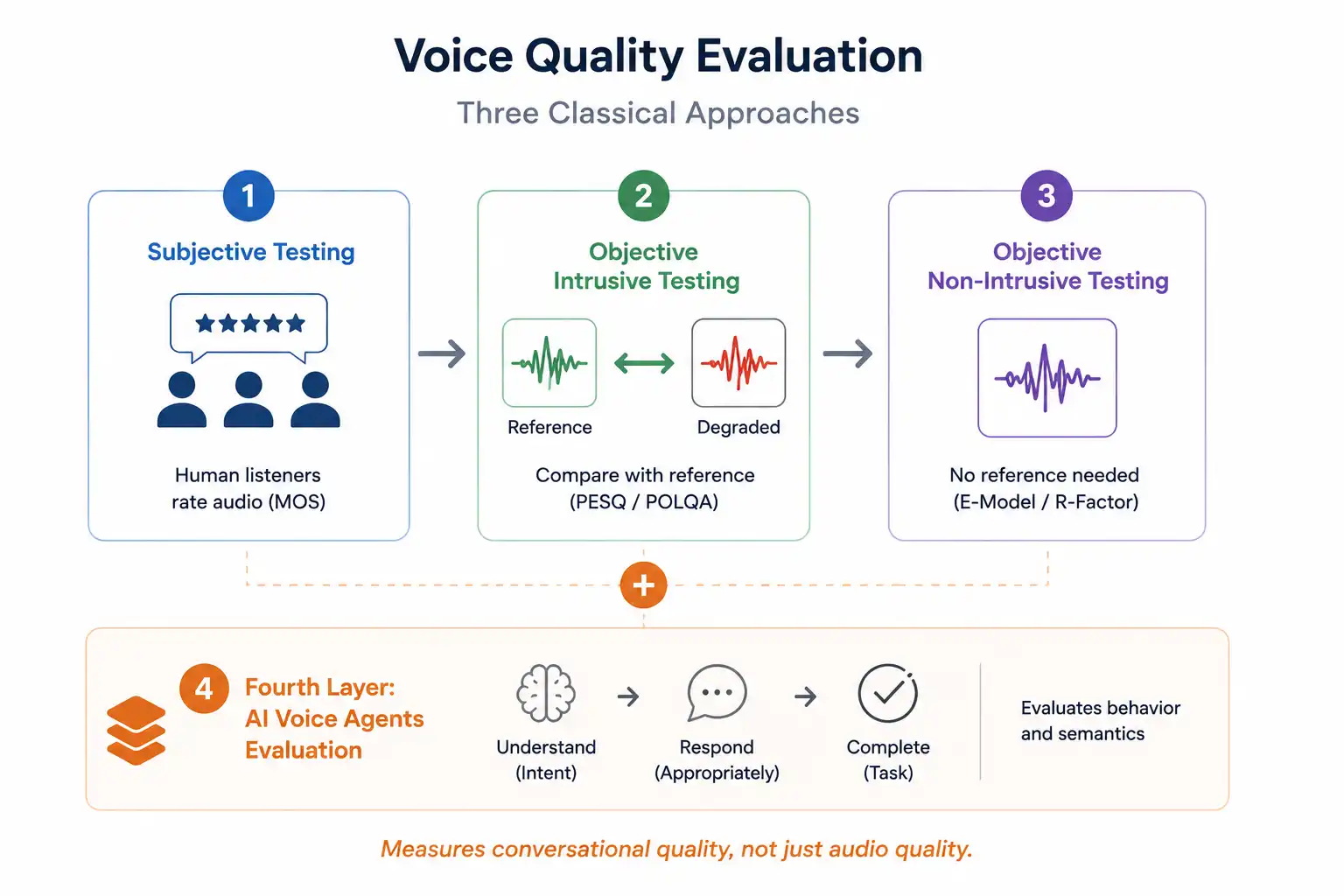
- Subjective testing: Involves human listeners rating audio samples on a scale, producing a Mean Opinion Score (MOS). Defined under ITU-T P.800, this method is the most perceptually accurate but is expensive, time-consuming, and impossible to run continuously at scale.
- Objective intrusive testing: Uses algorithms to compare a clean reference signal against the degraded signal received after transmission. PESQ (ITU-T P.862) and POLQA (ITU-T P.863) are the dominant standards here. Both produce a computational approximation of MOS without requiring human listeners.
- Objective non-intrusive testing: Evaluates the received signal alone, with no reference signal. This is the only method suitable for monitoring live calls in production, since injecting a reference signal mid-call is not practical. The ITU-T E-Model (R-Factor) is the most widely used non-intrusive standard for real-time VoIP quality estimation.
The Fourth Layer: AI Voice Agents
For AI voice agents, a fourth evaluation layer applies: behavioral and semantic evaluation, which assesses whether the voice agent understood the caller correctly, responded appropriately, and completed the task. Classical audio metrics cannot measure any of these. An agent can score 4.2 MOS and still fail 40% of its calls through poor intent classification or excessive response latency.
Why Voice Quality Testing Matters in 2026?
Voice quality testing matters in 2026 because contact center scale and rapid AI voice agent adoption have raised the stakes, and AI errors compound across stages rather than averaging out.
- Infrastructure Scale: Contact centers and enterprise VoIP systems handle massive call volumes. Poor audio quality lowers customer satisfaction, increases call abandonment, violates SLA commitments, and creates accessibility barriers for voice-dependent users.
- AI Voice Agent Adoption: According to Gartner, 40% of enterprise applications will feature task-specific AI agents by the end of 2026, up from less than 5% in 2025. Voice-first AI failures caused by poor transcription, latency, or broken conversations directly lead to escalations and abandoned interactions.
- Why Errors Compound: Voice AI systems depend on speech-to-text, natural language understanding, and text-to-speech working together. Since overall success is multiplicative, 90% accuracy across all three stages results in only ~73% end-to-end success, while 85% accuracy drops it to ~61%.
- Continuous Testing Requirement: Voice quality testing is no longer a periodic QA task. Modern voice systems require continuous, automated testing integrated into production and release pipelines.
Key Voice Quality Metrics You Need to Know
The metrics for VoIP and AI voice agents overlap in some areas and diverge sharply in others, understanding which metric measures what is essential before building any test plan.
Classical Voice Quality Metrics (VoIP and Network)
These metrics measure how cleanly audio travels across the network, independent of what is being said. They are the baseline every contact center monitors.
- MOS (Mean Opinion Score): The foundational 1-to-5 voice quality score (5 is excellent, 1 is unacceptable). Teams typically set 3.5 as the minimum acceptable threshold and target above 4.0.
| MOS Score | Quality Level | Practical Meaning |
|---|---|---|
| 4.3 to 5.0 | Excellent | Indistinguishable from high-quality telephony |
| 4.0 to 4.3 | Good | Toll quality; standard for enterprise VoIP |
| 3.5 to 4.0 | Acceptable | Minimum threshold for contact center use |
| 3.0 to 3.5 | Fair | Noticeable degradation; users may complain |
| Below 3.0 | Poor / Bad | Unacceptable for production use |
- PESQ (ITU-T P.862): An intrusive, reference-based algorithm that compares a clean signal to the received one for a MOS-equivalent score. Built into most commercial voice testing tools, but designed for traditional telephony and weaker on HD voice and 5G/VoLTE codecs.
- POLQA (ITU-T P.863): The current-generation successor to PESQ, with support for super-wideband (48 kHz) HD voice and VoLTE/5G delay patterns. The right standard for modern codecs (EVS, G.722, Opus) and 5G voice traffic.
- Jitter: Variation in packet arrival timing. Under 30ms maintains HD voice, 30 to 50ms is acceptable with buffering, above 50ms causes audible degradation, and above 100ms means severe loss.
- Latency (One-Way Delay): ITU-T G.114 recommends a maximum one-way delay of 150ms; above 200ms consistently correlates with reduced CSAT in contact centers.
- Packet Loss: Below 1% is imperceptible, 1–5% degrades progressively, and above 5% is unusable. Modern codecs like Opus conceal low-level loss.
- E-Model R-Factor (ITU-T G.107): A non-intrusive 0-to-100 score derived from network stats. Above 80 is good (MOS above 4.0), below 60 is unacceptable. Useful for live monitoring since it needs no reference signal.
AI Voice Agent Metrics
When the system on the other end is an AI agent, the metrics shift from audio transmission to the intelligence pipeline behind the voice.
- WER (Word Error Rate): Accuracy of the speech-to-text (STT) transcription layer, calculated as
(Substitutions + Deletions + Insertions) / Total Reference Words Ã 100. Target below 5% on clean audio, though 2025 benchmarks show leading models exceeding 20% on noisy speech, so testing under realistic acoustic conditions is critical. Mobile performance testing principles apply here too.
Note: WER measures transcription accuracy, not semantic accuracy. A transcript where "I want to cancel" is rendered as "I want to handle" has low WER impact but produces completely wrong intent classification downstream.
- TTFA (Time to First Audio): The primary latency metric for conversational voice AI, measuring the time from the user finishing to the agent's first audio. Deployed systems show a P50 of 1.4 to 1.7 seconds, roughly 5x slower than the 300ms humans expect.
| Component | Target |
|---|---|
| STT (transcription) | Under 200ms |
| LLM (time to first token) | Under 400ms |
| TTS (time to first audio byte) | Under 150ms |
| End-to-end P50 TTFA | Under 1.5 seconds |
| End-to-end P95 TTFA | Under 3 to 5 seconds |
Note: Always measure latency at P95 and P99 percentiles, not just averages. An average TTFA of 800ms can mask 10% of calls spiking to 3 seconds or more. Those are the calls where users hang up.
- Intent Accuracy: Whether the agent correctly classified what the caller wanted, independent of transcript accuracy. Strong WER can still mask misclassification from acoustic ambiguity or vocabulary gaps. The methods in NLP testing apply directly to building your intent accuracy test set.
- Task Success Rate (TSR) and First Call Resolution (FCR): TSR is the share of calls completed end-to-end without escalation; FCR is the share resolved in a single interaction. An FCR target of 85% or above is the industry standard.
- Barge-In Handling: When a caller interrupts mid-speech, the system must detect it, stop the current TTS output, and respond without losing context, which depends on strong speech synthesis API browser support.
Types of Voice Quality Testing
Voice quality testing requires different approaches depending on the system architecture, deployment stage, and production risk profile.
- Network-Level VoIP Testing: Validates the network path a voice call travels by simulating calls, capturing transmitted audio, and running PESQ or POLQA analysis. Common checks include call setup quality, routing variation, codec negotiation, and mid-call degradation under load.
- End-to-End IVR and Contact Center Testing: Validates the full customer call chain across carrier networks, IVR systems, switching infrastructure, and agent stations. Teams already using IVR automation testing can apply similar workflow validation patterns here.
- AI Voice Agent Testing: Focuses on conversational AI behavior rather than only audio transport. Testing covers transcription accuracy, latency distribution, intent classification, conversation flow, and end-to-end task completion. The methodology closely overlaps with how to test a chatbot for multi-turn interaction validation.
- Load and Performance Testing: Validates voice quality under concurrent traffic and production-scale demand. Performance testing for AI voice agents must include network load, STT API limits, LLM throughput, and TTS rendering capacity.
- Regression Testing After Updates: Ensures system quality remains stable after codec updates, prompt changes, IVR revisions, or model upgrades by comparing post-release metrics against established baselines.
How to Test Voice Quality: Step-by-Step
The right approach depends on the target: VoIP and IVR use a reference-signal workflow comparing clean and received audio, while AI voice agents need a scenario-driven conversational workflow.
Testing VoIP or IVR Voice Quality
This workflow validates the network path a call travels by comparing a clean reference signal against the received audio. Testing voice systems across varied network conditions is critical, much like teams test mobile websites on different network conditions , because real callers rarely operate on stable or clean connections.
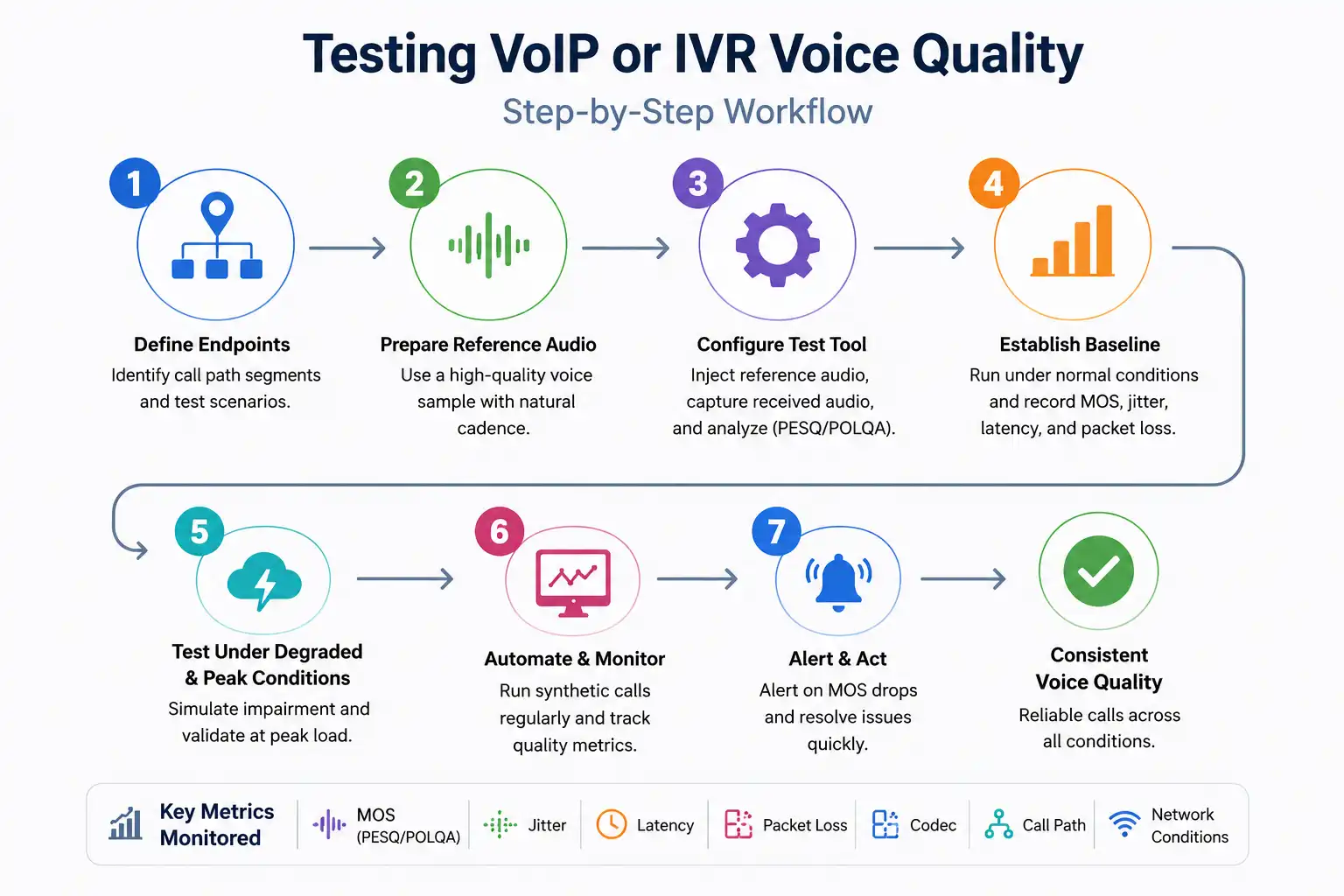
- Define your test endpoints: Identify every segment of the call path: customer device to IVR, IVR to switch, switch to agent station. Each is a separate test scenario in addition to a full end-to-end test.
- Prepare your reference audio: Select or record a high-quality, standardized voice sample with varied cadence, natural pauses, and a representative range of phonemes. Avoid artificially clean studio recordings that do not reflect real-world call conditions.
- Configure your test tool: Set up your testing platform to inject the reference audio at the origination point, capture the received audio at the destination endpoint using standard audio capture APIs like MediaRecorder, verify MediaRecorder browser support across target environments, and feed both into a PESQ or POLQA analysis engine.
- Establish your MOS baseline: Run the test under normal conditions to establish a baseline MOS, jitter, latency, and packet loss measurement. Document the codec, call path, and network conditions. This baseline becomes your regression reference for all future tests.
- Test under degraded and peak conditions: Introduce controlled network degradation, packet loss simulation, bandwidth throttling, and latency injection to understand how your system degrades. Then run load tests at your expected peak concurrent call volume.
- Automate and schedule continuous monitoring: Schedule synthetic test calls every 15 to 30 minutes for high-criticality environments and alert on MOS drops below your minimum threshold. For browser-based voice apps, understanding how the Web Audio API captures and processes audio is essential context for interpreting what your test tooling measures.
Testing AI Voice Agent Quality
Testing an AI voice agent measures the intelligence pipeline, not just the audio path. A structured approach to voice observability keeps the continuous monitoring step tractable at scale.
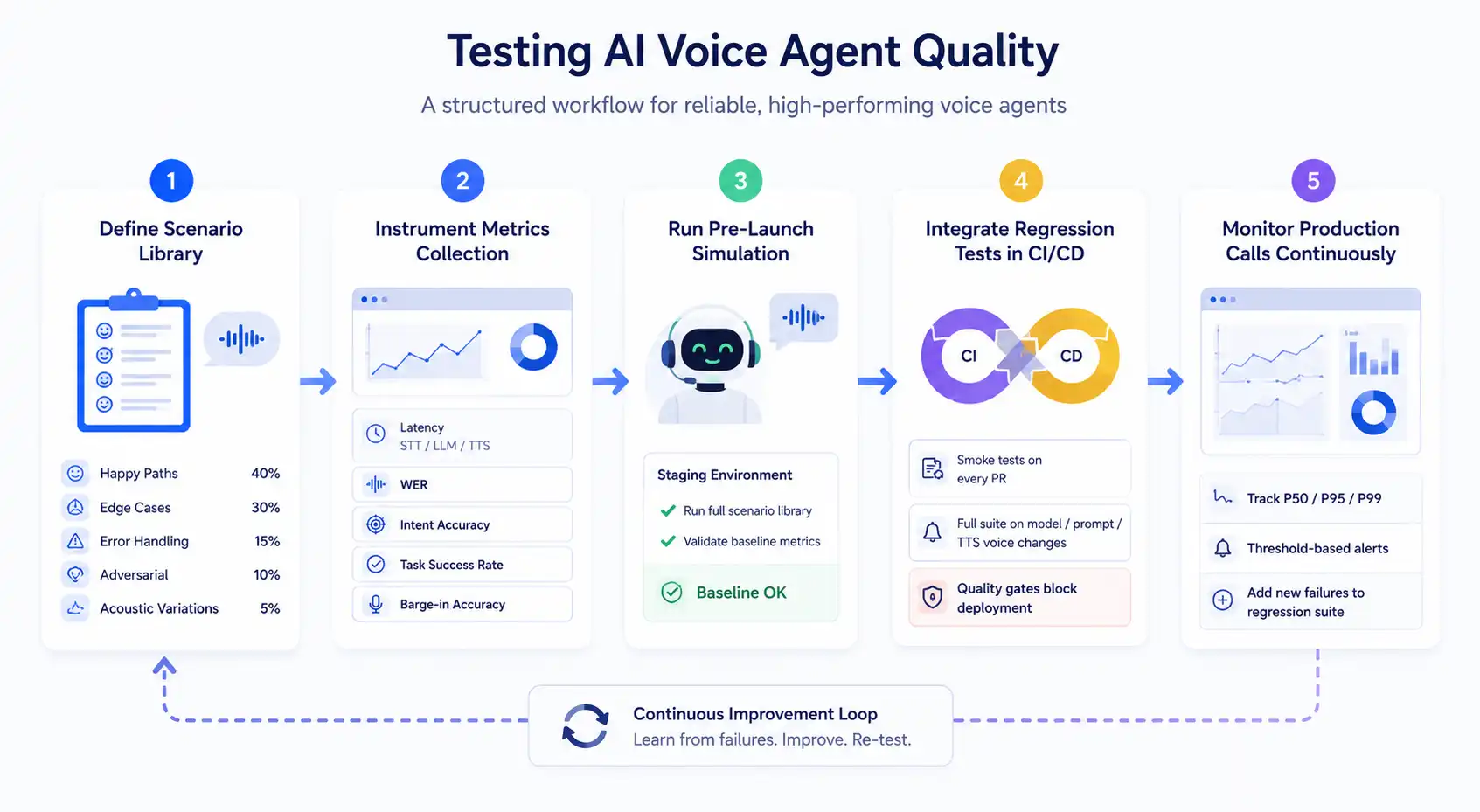
- Define your scenario library: Build a structured set of test conversations covering the full range of user interactions. A well-structured scenario library follows this composition:
- Instrument your metrics collection: Ensure measurement is in place for all critical dimensions: per-component latency (STT, LLM TTFT, TTS), WER on a held-out transcription test set, intent accuracy against labeled ground truth, task success rate per scenario category, and barge-in detection accuracy.
- Run pre-launch simulation: Execute your full scenario library against the agent in a staging environment before any production deployment. This validates that baseline metrics are within acceptable thresholds and identifies failure modes that manual testing would miss.
- Integrate regression tests into your CI/CD pipeline: Run a fast smoke test suite on every pull request. Run the full scenario suite on every model version change, prompt update, or TTS voice change. Set quality gates that block deployment if key metrics drop below your defined thresholds.
- Monitor production calls continuously: Track your key metrics at P50, P95, and P99 percentiles with threshold-based alerting. Every production failure that exposes a new failure mode should be added to your regression suite immediately.
| Scenario Type | Share | What It Covers |
|---|---|---|
| Happy paths | 40% | Standard flows where intent is clear and the agent completes the task |
| Edge cases | 30% | Multi-intent requests, corrections mid-conversation, topic switches |
| Error handling | 15% | Invalid inputs, timeout scenarios, out-of-scope requests |
| Adversarial | 10% | Prompt injection attempts, guardrail bypass, repeated failures |
| Acoustic variations | 5% | Noisy environments, strong accents, low-bandwidth audio |
Testing Voice Quality on Voice Agent Testing Platforms?
TestMu AI (Formerly LambdaTest) validates AI voice agents through automated, end-to-end conversational testing across voice and chat, scoring each call on multiple quality dimensions.
The platform automatically generates realistic scenarios, executes multi-turn interactions, and evaluates behavior across multiple quality dimensions.
As enterprise AI agents move from pilot deployments into production systems handling real customer interactions, testing infrastructure must deliver the same rigor expected from modern automation testing platforms and large-scale software release pipelines.
Manual call reviews and spot-checking do not scale effectively when a single prompt update or STT model change can impact thousands of interactions. The platform supports inbound calls, outbound calls, chat agents, webhook agents, and AI-generated image evaluation. For voice quality validation, the Phone Caller workflow is the primary testing path.
The platform supports four interaction modalities: inbound phone calls, outbound phone calls, chat and webhook agents, and AI-generated image evaluation. For voice quality testing specifically, the Phone Caller agent type is the relevant path.
How Does Voice Agent Testing Work?
This voice agent testing platfrom by TestMu AI deploy a testing AI agent that simulates realistic caller behavior against the target voice agent. Unlike static scripted replay systems, the testing agent dynamically adapts its responses during multi-turn conversations, making it highly effective for validating enterprise AI agents in production-like scenarios.
This approach helps uncover conversational failure modes such as context loss, incorrect mid-conversation corrections, escalation failures, and abandoned flows that often remain hidden in traditional automation testing tools.
The platform is telephony-provider agnostic, allowing teams to integrate existing providers without changing their voice infrastructure stack.
Setting Up Your First Phone Agent Test
- Install the CLI: Install the
testmu-a2aCLI before configuring your voice agent tests.pip install testmu-a2a-cli - Authenticate: Authenticate using your TestMu AI username and access key.
testmu-a2a auth -u <username> -k <access_key>
For CI/CD pipelines, configure environment variables instead:
export TESTMU_USERNAME=<username>
export TESTMU_ACCESS_KEY=<access_key>
export TESTMU_BASE_URL=https://agent-testing.lambdatest.comtestmu-a2a projects create --name "Voice Agent QA" --description "Inbound voice agent regression suite" --type phone_caller_inboundtestmu-a2a prompts set --project <project_id> --prompt-file prompt.yamlExample prompt.yaml:
prompt: |
You are a customer support voice agent for a SaaS product.
You help users with billing, account issues, and technical troubleshooting.
Always verify the user's account email before making changes.
Escalate to a human if the customer requests a refund over $500.
context: "Agent must comply with GDPR and never store PII in call logs"
files:
- ./compliance_rules.pdf
- ./product_faq.md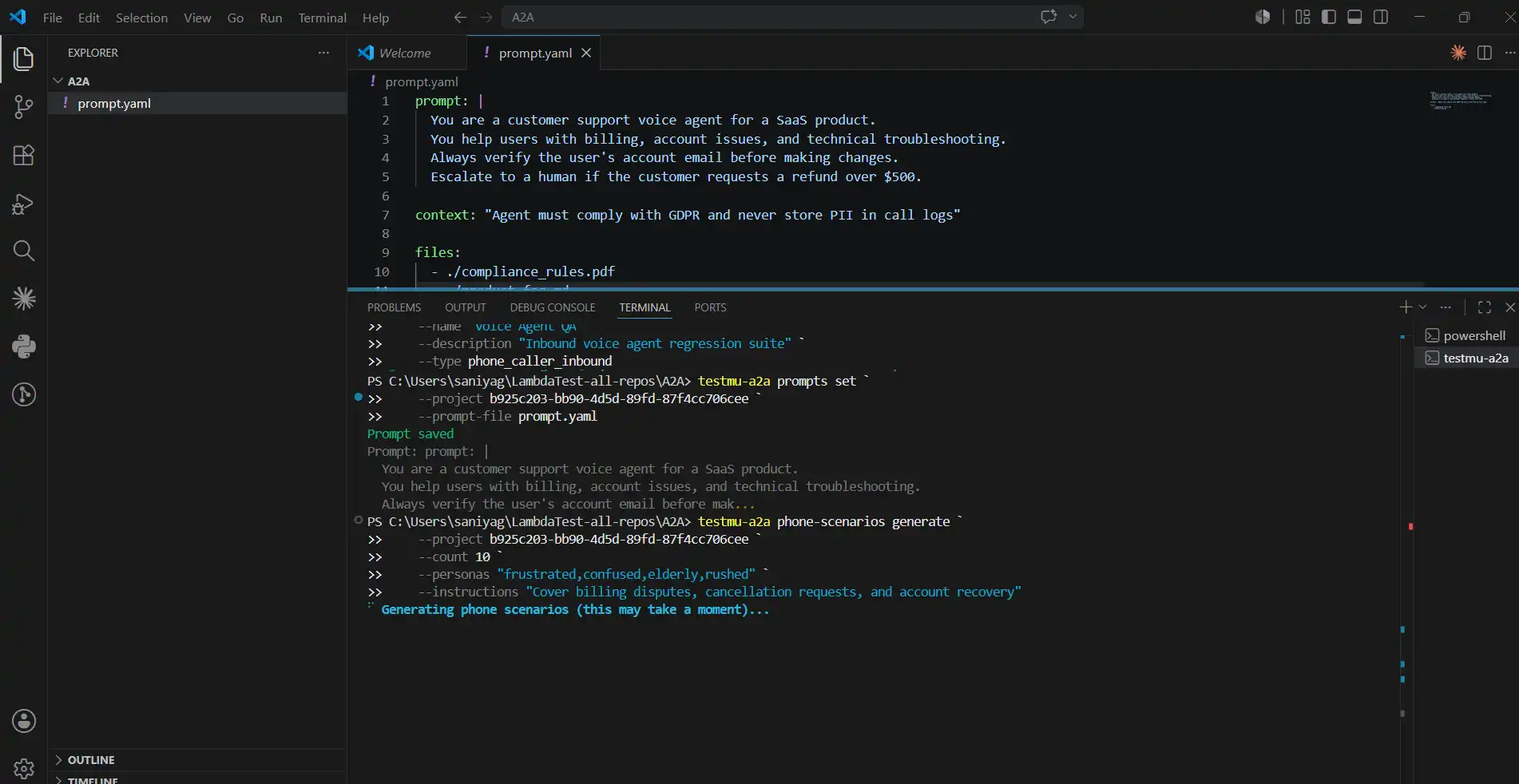
testmu-a2a phone-scenarios generate --project <project_id> --count 10 --personas "frustrated,confused,elderly,rushed" --instructions "Cover billing disputes, cancellation requests, and account recovery"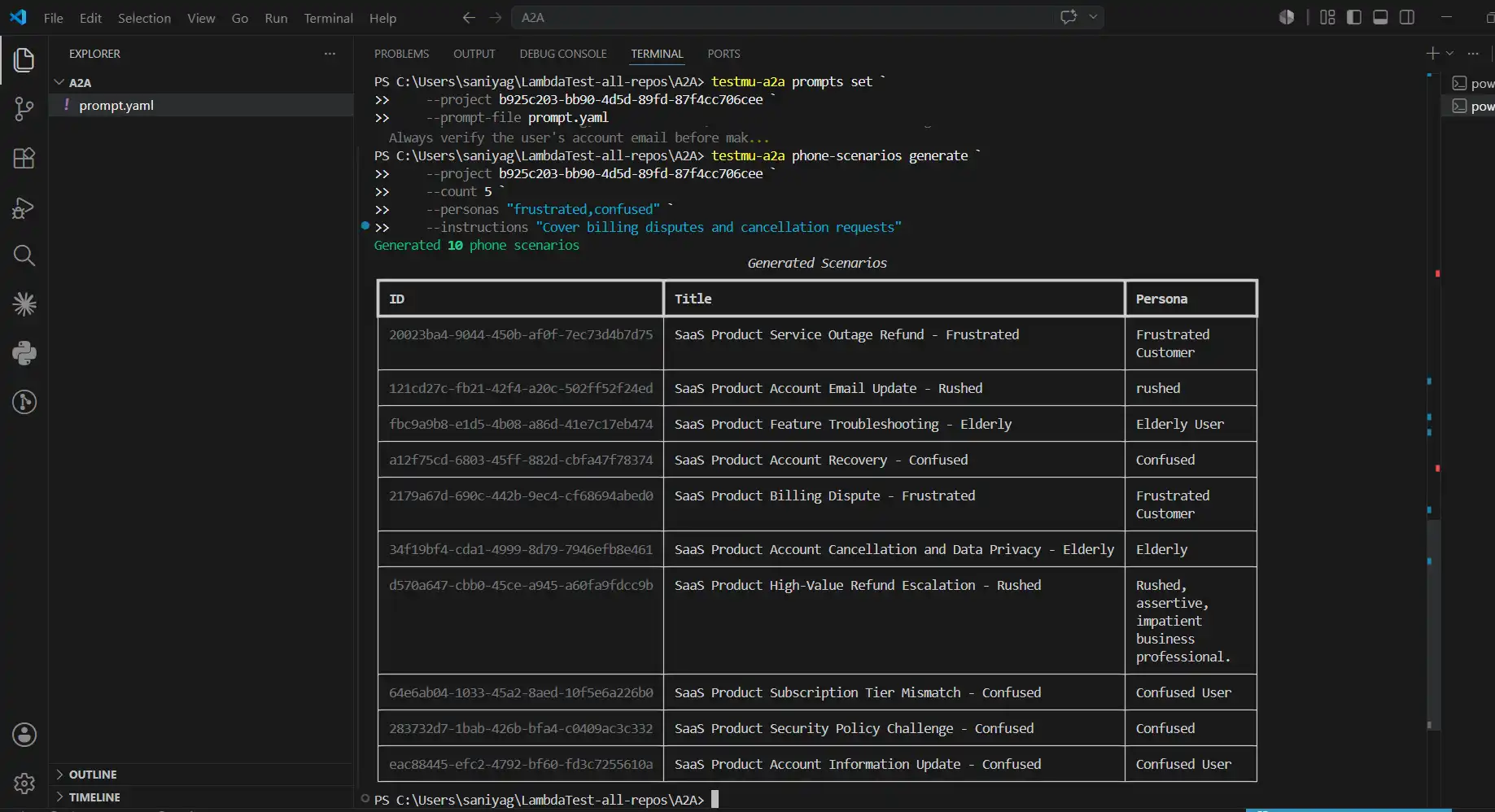
testmu-a2a suites create --project <project_id> --name "Voice Regression Suite" --scenarios "<scenario_id_1>,<scenario_id_2>,<scenario_id_3>"For per-scenario voice configuration, use a suite.yaml file:
scenarios:
- id: <scenario_id_1>
phone_number: "+15551234567"
voice: Sara
voice_provider: azure
background_sound_url: https://example.com/office-noise.mp3
background_sound_enabled: true
- id: <scenario_id_2>
phone_number: "+15551234567"
voice: Brian
voice_provider: azuretestmu-a2a suites run --project <project_id> --name "Voice Regression Suite" --number +15551234567 --voice Sara --voice-provider azureResults:
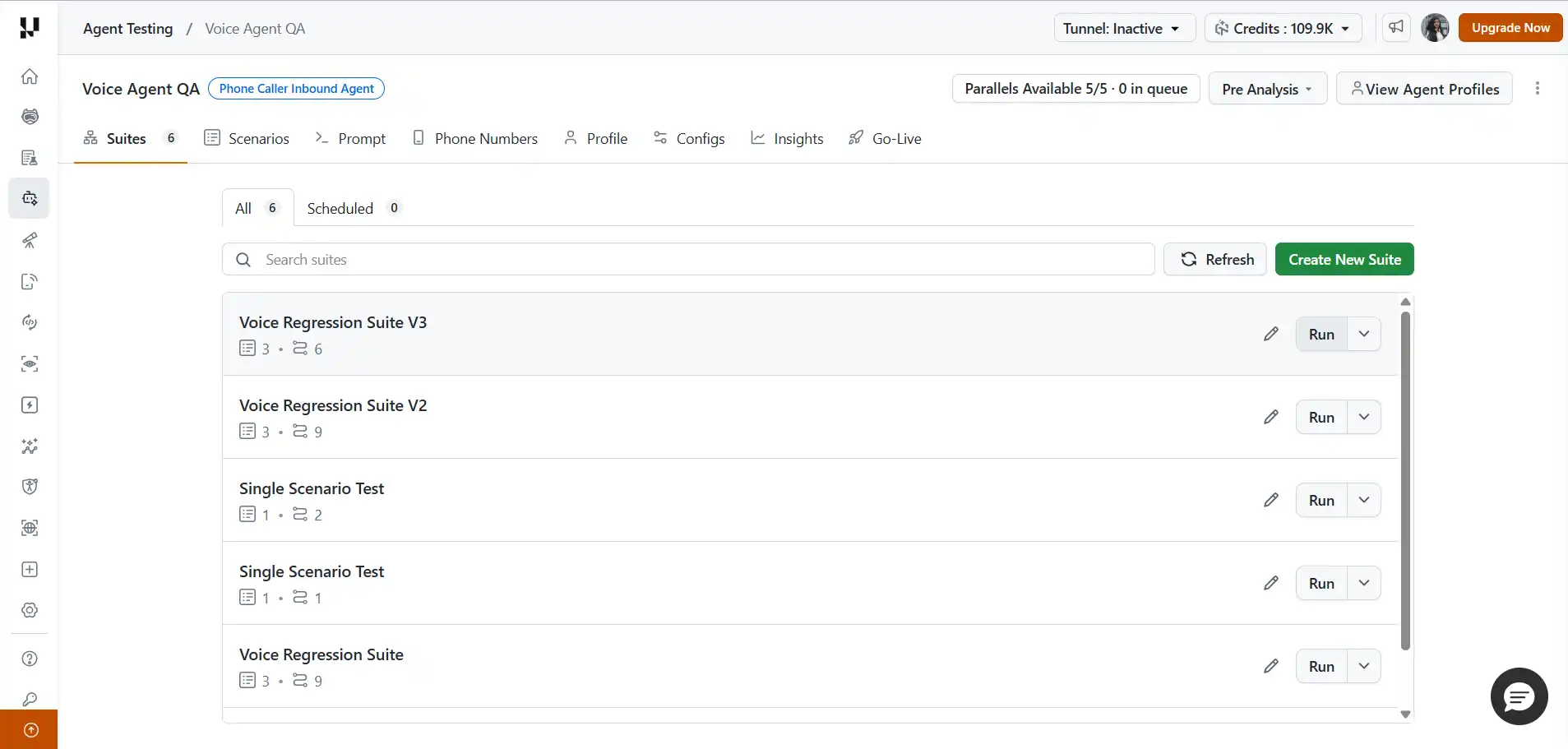
To get started with voice agent testing on agent testing platform follow the support documention on getting started with Agent testing platform
What Does this Agent Testing Platform Evaluates?
This voice agent by TestMu AI evaluates end-to-end voice AI performance across conversational quality, operational efficiency, and audio intelligence metrics.
- Conversation Flow and Interaction Dynamics: Turn-taking, barge-in handling, interruption recovery, and context retention across multi-turn conversations.
- Accuracy and Effectiveness: Intent classification accuracy, factual correctness, task completion rate, and hallucination detection across dynamic customer interactions.
- User Experience and Satisfaction: Response naturalness, empathy signals, phrasing clarity, conversation friction, and accessibility testing considerations for voice-first experiences.
- Business Operational Metrics: First call resolution, escalation rate, call handle time, and policy compliance tracking for production support environments.
- Audio Voice Quality: MOS-equivalent scoring, background noise tolerance, audio clarity, and performance consistency under varied network conditions.
- Speech-to-Text Evaluation: WER measurement, transcription latency, confidence scoring across acoustic conditions, and automated accessibility testing coverage for voice reliability validation.
- Validation Results: Per-scenario pass/fail validation against defined quality criteria with evidence-backed confidence scoring and regression tracking.
- Detected Issue Tags: Automated detection of failure patterns including barge-in failures, hallucinated confirmations, context drops, off-topic responses, and conversation recovery failures.
What to Test for AI Voice Agent Quality
When you configure your initial test suite in the platform, the following scenario categories should always be present:
- Core task flows: Every primary use case your voice agent handles needs a test case validating correct task completion end-to-end. These are your happy path scenarios and should make up roughly 40% of your suite.
- Caller correction handling: Test scenarios where the caller says something, then corrects it: "Actually, I meant Tuesday, not Thursday." The agent must update its understanding and not proceed with the original information.
- Multi-intent requests: Real callers often combine requests: "I want to change my appointment and also ask about my balance." Test whether your agent handles both intents and addresses them in the right order.
- Barge-in and interruption: Test scenarios where the caller interrupts the agent mid-response. The agent should stop speaking, acknowledge the interruption, and respond to the new input without losing conversation context.
- Escalation triggers: Test scenarios where the caller's request falls outside the agent's scope or the caller explicitly requests a human. Validate that escalation happens correctly and conversation context is handed off appropriately.
- Adversarial inputs: Test inputs designed to confuse or manipulate the agent: off-topic requests, attempts to get the agent to behave outside its defined scope, and repeated failed interactions. The platform supports red team security testing via for a full adversarial assessment.
- Adversarial and Security Testing: Test inputs designed to confuse or manipulate the agent, including off-topic requests, attempts to force behavior outside its defined scope, and repeated failed interaction scenarios.
The platform also supports advanced red team security testing through
testmu-a2a redteamfor comprehensive adversarial assessment. To get started with voice agent security testing, follow the support documentation on Running Red Team Security Tests.
Common Voice Quality Issues and How to Diagnose Them
Most voice quality complaints trace back to a short list of recurring failure modes. Each pattern below pairs a symptom with the metric to measure and the most likely root cause.
Network-Level Issues
These problems originate in the transport and network layer, so they affect VoIP, IVR, and AI voice agents alike, and usually surface before any AI logic is even involved.
Issue #1: Jitter and Choppy Audio
- Challenge: Speech sounds broken, words cut in and out, audio stutters.
- Solution: Measure jitter at the network level. Jitter above 30ms with inadequate jitter buffer configuration is the primary cause. Check for network congestion, QoS misconfiguration, and jitter buffer settings that are too small for the observed network conditions.
Issue #2: Echo
- Challenge: The speaker hears their own voice returned with a delay.
- Solution: Echo is caused by acoustic coupling at the far end or electrical echo in the transmission path. Measure round-trip delay, since echo above 150ms one-way is highly noticeable. Check echo cancellation configuration on the endpoint and IVR hardware.
Issue #3: Robotic or Metallic Audio
- Challenge: Voice sounds distorted, synthetic, or metallic.
- Solution: Usually caused by codec compression artifacts, packet loss concealment introducing audio artifacts, or mismatched codec negotiation between endpoints. Check that codec settings match across the call path and that the audio sample rate is consistent.
Issue #4: Clipping
- Challenge: Words are cut off at the beginning or end of utterances.
- Solution: In VoIP systems, clipping is commonly caused by Voice Activity Detection (VAD) misconfiguration. In AI voice agents, clipping can result from barge-in detection that triggers too early, cutting off the caller before they finish speaking.
Issue #5: High Latency / Conversational Delay
- Challenge: Awkward pauses in conversation, parties talking over each other.
- Solution: For VoIP, measure one-way latency. Above 150ms one-way, conversational naturalness degrades. For AI voice agents, instrument component-level latency (STT, LLM, TTS) separately. Latency spikes that appear as P95 outliers rather than elevated averages indicate capacity constraints under load rather than a structural architecture problem.
AI Voice Agent Issues
These failure modes are specific to AI-driven voice agents. They live in the speech-to-text, LLM, and memory layers rather than the network, and won’t show up in traditional VoIP metrics.
Issue #1: High WER and Misunderstood Intent
- Challenge: The AI agent responds inappropriately or asks for repetition frequently.
- Solution: Run WER measurement on a sample of call transcripts against human-verified ground truth. WER above 10% on your production audio profile indicates an STT model mismatch. Check whether your STT provider has been evaluated on audio matching your actual call conditions: mobile callers, background noise, domain vocabulary.
Issue #2: Hallucinated Confirmations
- Challenge: The agent confirms information the caller did not provide, or confirms completing a task it did not execute.
- Solution: This is an LLM-layer failure, not an audio quality problem. It surfaces through task success rate measurement and manual review of failed call traces. For background on how AI chatbot architectures handle conversational state, which directly affects multi-turn test scenario design, the learning hub entry covers the foundations.
Issue #3: Context Drop Across Turns
- Challenge: The agent forgets information the caller provided earlier in the same conversation.
- Solution: This is a context window or memory management failure. Reproduce the issue with a multi-turn test scenario that places the relevant information early in the conversation and references it late. The TestMu AI platform's Context Memory agent category specifically covers this failure class.
Voice Quality Testing Best Practices
These practices apply across VoIP, IVR, and AI voice agent testing. They represent the operational discipline that separates teams that ship reliable voice systems from those that discover problems in production.
- Use objective metrics as your primary measure, not listener feedback. Human-reported quality issues are lagging indicators. Continuous automated measurement with MOS, jitter, and latency gives you leading indicators that catch degradation before it reaches your users.
- Establish baselines before making any changes. Never deploy a network change, codec update, prompt modification, or model version change without a documented pre-change baseline. Regression is only measurable against a known reference state.
- Measure latency at percentiles, not averages. A P50 TTFA of 900ms can coexist with a P95 of 4 seconds. Users who experience P95 interactions are the ones who hang up and do not return. Always report P50, P90, and P95 together, never averages alone.
- Test on audio that matches your production conditions. A voice system that scores 95% accuracy on clean audio may fail at 70% accuracy on mobile calls in real environments. Test with audio reflecting actual caller conditions: varying network quality, background noise, regional accents, and low-bandwidth scenarios.
- Integrate voice quality testing into your CI/CD pipeline. Every voice system change (IVR update, LLM version change, TTS voice swap, prompt edit) should trigger an automated regression test run before reaching production. Quality gates that block deployment on metric regression prevent most production voice quality incidents.
- Run load tests before every significant traffic increase. Capacity that handles your current concurrent call volume may degrade at 2x or 3x that volume. Run load tests simulating peak traffic before major campaigns, product launches, or seasonal volume spikes.
- Build your regression suite from production failures. Every call that fails in production and exposes a new failure mode is a test case you did not have before. Capture the call trace, add the scenario to your regression suite, and run it on every future release.
- Separate audio quality testing from AI behavior testing. These are distinct concerns with different measurement tools. A voice agent can have excellent MOS scores and terrible task success rates. Test both layers independently and report on both.
- Document pass/fail thresholds and enforce them. Define your minimum acceptable MOS, maximum acceptable TTFA, maximum acceptable WER, and minimum acceptable FCR, then enforce them as deployment gates. In TestMu AI, configure these per project with
testmu-a2a thresholds set. - Consider usability alongside technical metrics. Usability testing surfaces perceived quality issues (response phrasing, conversation flow awkwardness, interaction friction) that objective audio metrics do not capture. Combining both layers gives a complete picture of the voice experience.
- Review your test scenarios regularly. Voice systems change continuously with new features, new conversation flows, and new user behaviors. Schedule quarterly reviews to add new scenarios, retire obsolete ones, and recalibrate your baselines.
Conclusion
Voice quality testing in 2026 is two disciplines running in parallel: validating the network path a call travels, and validating the AI pipeline that decides what the voice says.
For VoIP and IVR systems: establish a MOS baseline with PESQ or POLQA and schedule continuous synthetic calls with threshold-based alerting. For AI voice agents: build a scenario library, measure WER, TTFA, intent accuracy, and task success rate, and gate every release on those thresholds.
TestMu AI's Agent Testing Platform places real calls to your voice agent, scores each conversation across more than fifteen quality dimensions across eight metric categories, and returns a Go-Live readiness verdict before you ship. The platform reads your agent's prompt and documentation to generate deployment-ready test cases automatically, so teams without a dedicated QA function can achieve professional-grade voice agent validation from day one. For systems that authenticate callers by their voiceprint, the same rigor extends to voice biometrics testing.
Author
Saniya Gazala
Blogs: 49
Saniya Gazala is a Product Marketing Manager and Community Evangelist at TestMu AI with 2+ years of experience in software QA, manual testing, and automation adoption. She holds a B.Tech in Computer Science Engineering. At TestMu AI, she leads content strategy, community growth, and test automation initiatives, having managed a 5-member team and contributed to certification programs using Selenium, Cypress, Playwright, Appium, and KaneAI. Saniya has authored 15+ articles on QA and holds certifications in Automation Testing, Six Sigma Yellow Belt, Microsoft Power BI, and multiple automation tools. She also crafted hands-on problem statements for Appium and Espresso. Her work blends detailed execution with a strategic focus on impact, learning, and long-term community value.



Frequently asked questions
Did you find this page helpful?
More Related Blogs
TestMu AI forEnterprise
Get access to solutions built on Enterprise
grade security, privacy, & compliance
- Advanced access controls
- Advanced data retention rules
- Advanced Local Testing
- Premium Support options
- Early access to beta features
- Private Slack Channel
- Unlimited Manual Accessibility DevTools Tests