
Test the AI Agents You Build on Emergent
Emergent vibe-codes your app, but the agent inside must answer customers and call your tools correctly. Deploy AI evaluators to test it across thousands of scenarios for hallucinations and broken tool calls.
Automate Browser Flows from your
Terminal with Kane CLI

Trusted by 2M+ users globally at




"We have tripled our tests and are now executing tests in less than 2 hours with 78% Faster Test Execution"


"We figured out a more efficient way to monitor system health and resolve failures earlier in lower environments."





"TestMu AI has significantly boosted our testing speed, is easy to implement, and provides exceptional support."


"With 70% faster test execution, TestMu AI helped us achieve faster time-to-market and enhanced CX."



Deep Dive into Emergent Testing
Deploy AI evaluators that chat with your Emergent agent across thousands of scenarios, scoring 9 quality metrics and catching hallucinations and broken tool calls.
Test the Chatbots in Your Emergent App
Emergent builds chatbots that answer real users. Score every conversation across 9 quality metrics, including hallucination, bias, and context accuracy.

9 Quality Metrics
When a user asks your Emergent app to cancel a subscription or check an order, score the reply on bias, hallucination, completeness, and context awareness.
Scenarios From Your Spec
Auto-generate 60-100+ test scenarios from the PRD or product brief you prompted Emergent with, plus connected JIRA, Confluence, and GitHub.
Go-Live Assessment
Get a Green, Yellow, or Red production-readiness verdict before you publish an Emergent app or push a prompt-driven change.
Complete Emergent Testing Coverage
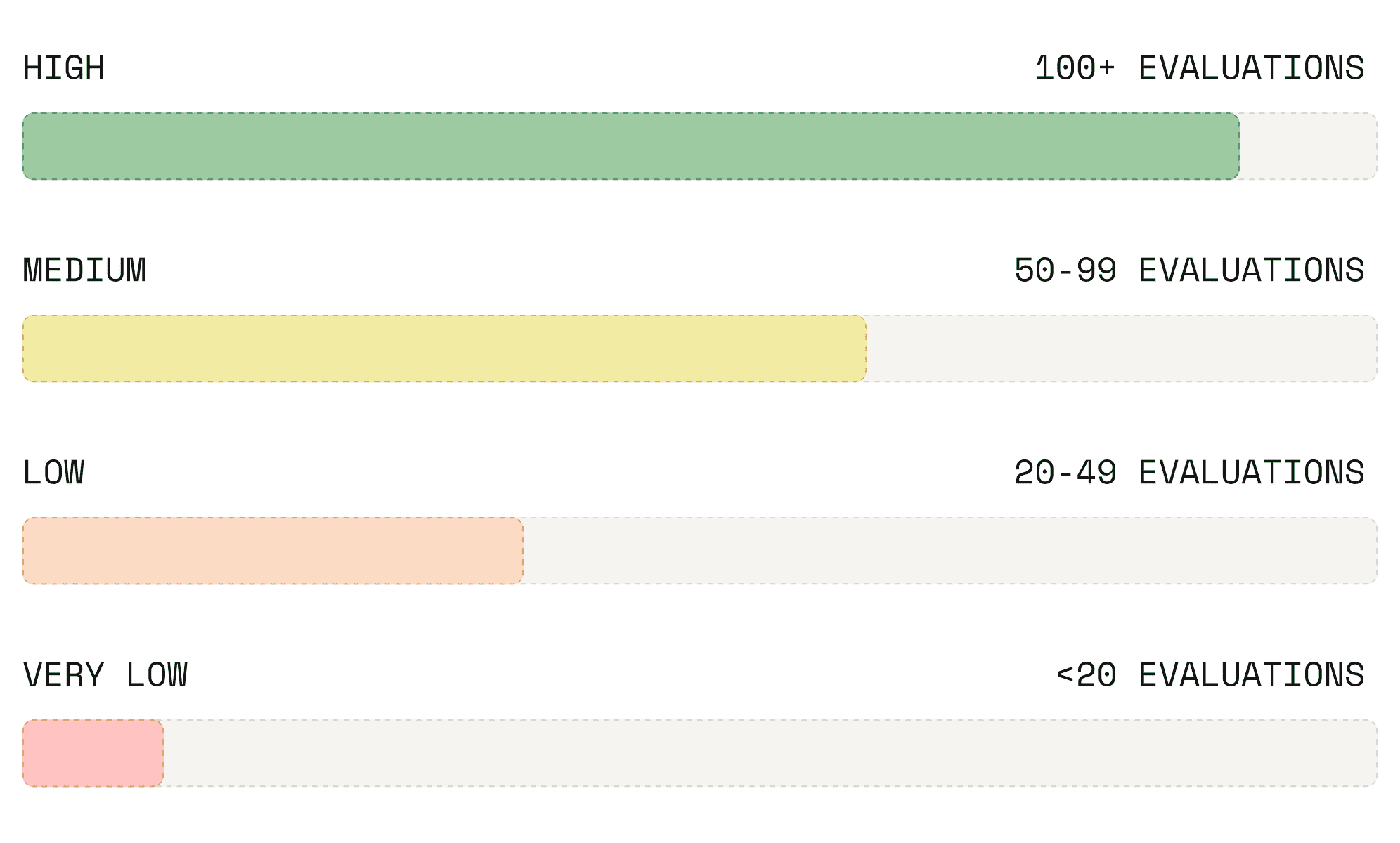
Confidence by Evaluation Volume
HIGH (100+ evaluations), MEDIUM (50-99), LOW (20-49), VERY LOW (below 20). Confidence scales with how many scenarios you run against your app.
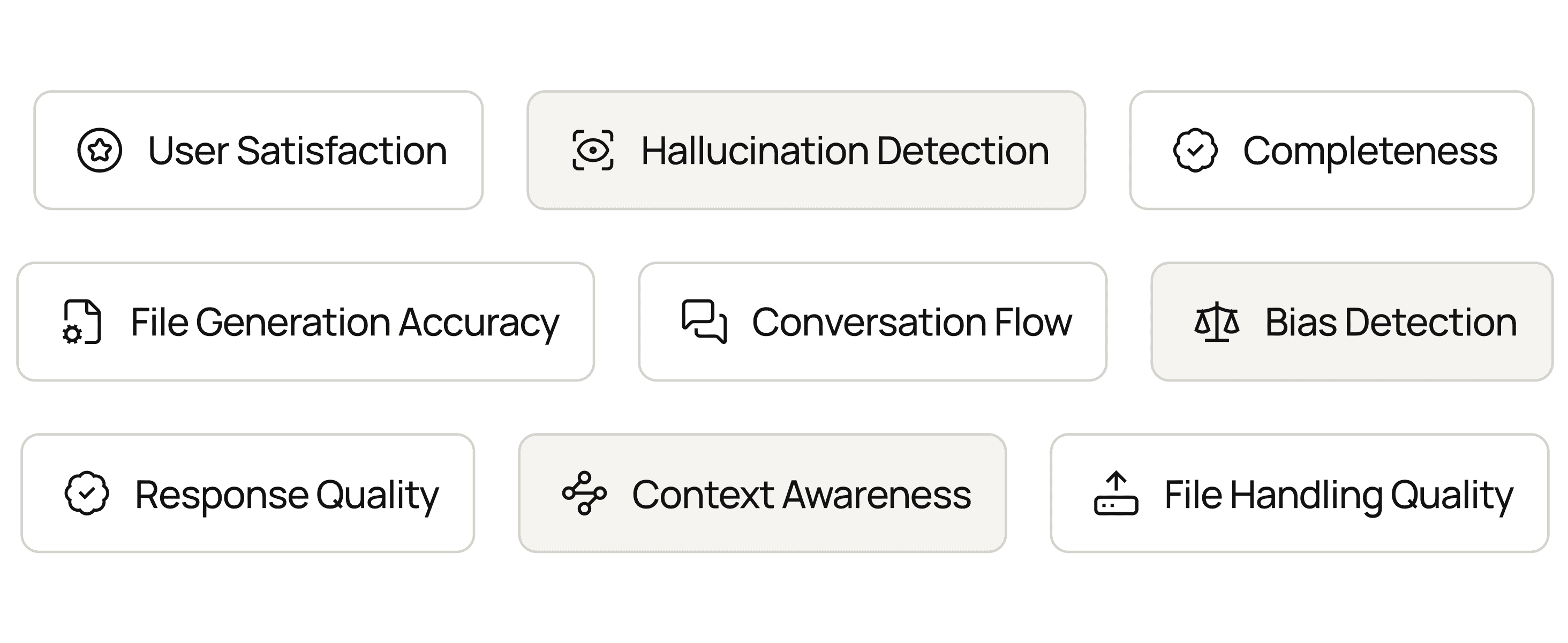
9 Quality Metrics Across Every Conversation
Score each reply from your Emergent app on bias, hallucination, completeness, context awareness, response quality, flow, user satisfaction, file handling, and accuracy.
4-Dimension Go-Live Assessment
Before you publish an Emergent app, each run scores Functional Completeness, Quality Standards, Risk Profile, and Operational Readiness, weighted 25% each.
Pass/Fail Analysis Output
Pinpoint every match and discrepancy in your Emergent agent's replies and tool calls, tracked as Pass, Fail, or Partial against your criteria.

Built for Every Layer of Emergent QA
Project and Environment Management
Keep separate test projects per Emergent app and scope staging and production variables with bulk creation support.
Test Profiles and Personas
Inject reusable test data and run scenarios across a pre-built or custom persona library to probe your chatbot from every user angle.
Custom Validation Criteria
Define evidence-based pass/fail rules per scenario, such as confirming a Stripe charge fired, with High/Medium/Low confidence tracking.
Security and Infrastructure
Execute via HyperExecute with optional secure tunnels to reach your deployed Emergent app behind a firewall.
Scheduling Engine
Re-run suites after each prompt edit using preset frequencies or custom cron expressions with IANA timezone support.
Observability and Reporting
Monitor agent performance across runs with unified dashboards, exportable reports, and real-time quality trends.
Success Stories of TestMu AI (Formerly LambdaTest)

50%
reduction in test execution time
“HyperExecute is a highly reliable test execution platform and has excellent customer support.”
Sagar Uday Kumar
Sr. Engineering Manager
Some Love from our Customers
As Best Egg expanded its product offerings and entered new markets, we knew our old testing infrastructure couldn’t keep up.
With support from Tenny Agustin, our Engineering Operations Lead, we modernized our approach with
TestMu AI

Best Egg
best-egg

Excited to Share My Learning Journey with Kane AI & Lambda Tool!
I'm pleased to announce that I've recently gained hands-on experience exploring Kane AI through the Lambda Tool and it’s been a fantastic journey of upskilling!
KaneAI

Suryateja Goud
suryateja-goud
See how is #Futureready to enable blazing-fast test orchestration seamlessly integrated with organizations' existing CI/CD platforms, using #Microsoft Azure.
TestMu AI

Microsoft India
MicrosoftIndia
Frequently asked questions
TestMu AI forEnterprise
Get access to solutions built on Enterprise
grade security, privacy, & compliance
- Advanced access controls
- Advanced data retention rules
- Advanced Local Testing
- Premium Support options
- Early access to beta features
- Private Slack Channel
- Unlimited Manual Accessibility DevTools Tests