
Next-Gen App & Browser Testing Cloud
Trusted by 2 Mn+ QAs & Devs to accelerate their release cycles

On This Page
- Importance of Testing AI Applications
- Types of AI Application Testing
- Criteria for Testing AI Applications
- Key Factors in Testing AI Applications
- How to Test AI Applications?
- TestMu AI–Driven Testing of Agentic AI Applications
- Top Tools for Testing AI Applications
- Common Challenges in Testing AI Applications
- Best Practices for Testing AI Applications
Testing AI Applications: Types, Tools, Steps and Best Practices
Testing AI applications the right way starts here. This guide covers types, tools, key challenges, step-by-step process, and best practices for QA teams shipping AI.

Saniya Gazala
March 23, 2026
AI is no longer confined to research labs or tech giants. It is in your bank's fraud detection engine, your company's customer support chatbot, and the recommendation system surfacing products on your e-commerce platform. And as AI embeds itself deeper into production systems, testing AI applications has become a non-negotiable part of shipping software.
According to McKinsey's 2025 State of AI survey, 88% of organizations now use AI in at least one business function, up from 78% the year before. Every one of those deployments is a system that needs to be tested.
Testing AI applications is not a niche concern for ML teams. It is a quality engineering problem that has made AI in software testing a core competency for any team shipping software with AI components, whether that is a customer-facing chatbot, a document processing pipeline, or an LLM-powered internal tool. And it is meaningfully harder than testing the software on which most QA teams have built their skills.
Overview
Why Testing an AI Application Is Essential?
AI isn't just about performance; it's about trust. In high-stakes use cases, failures can have serious consequences. Testing ensures reliability, fairness, and compliance before real-world impact.
- Accuracy is not guaranteed by design: AI outputs vary since models rely on patterns, not fixed facts.
- Bias can be invisible until it causes harm: Hidden data bias can unfairly impact users without obvious signs.
- Regulatory exposure is real: Laws require proper validation, testing, and audit trails for AI systems.
- Production behavior differs from test behavior: Real users introduce edge cases not seen in controlled testing.
- Trust, once lost, is hard to recover: One failure can significantly damage user confidence and credibility.
How AI Testing Differs From Traditional Testing
AI systems don't follow fixed rules; they generate probabilistic outputs. This makes testing less about correctness and more about evaluating quality.
- Deterministic vs probabilistic behavior: Traditional systems give consistent outputs; AI can vary responses for the same input.
- Exact validation vs quality evaluation: Traditional testing checks correctness; AI testing measures output quality, bias, and reliability.
What Is the Process for Testing AI Applications?
AI testing is a continuous process across the lifecycle, not just a pre-launch step. It focuses on measuring quality, risk, and real-world behavior—not just correctness.
- Define intended behavior: Clearly specify expected outcomes, limits, prohibited outputs, and escalation rules.
- Build a representative test dataset: Include normal, edge, adversarial, and multi-turn conversational scenarios.
- Establish evaluation criteria: Define how to measure accuracy, bias, tone, and hallucination rates.
- Run baseline testing before deployment: Create benchmarks to compare future model performance and detect regressions.
- Implement continuous monitoring in production: Track real usage, detect anomalies, and review outputs post-deployment.
- Test for adversarial inputs: Simulate prompt injections and edge cases to expose vulnerabilities.
- Document and track results: Record test outcomes, model versions, and issues for compliance and improvement.
Why Testing AI Applications Matters?
Testing AI applications matters because AI makes probabilistic decisions in high-stakes contexts, and failures can erode trust, introduce bias, and create regulatory risk.
The obvious answer is quality. But the more honest answer is trust.
AI makes probabilistic decisions in high-stakes contexts. It influences outcomes in healthcare, finance, legal tech, and HR. When it gets things wrong, the consequences are rarely just a broken UI or a 404 error.
According to a Deloitte Global Survey, 47% of enterprise AI users made at least one major business decision based on hallucinated content in 2024. That is the clearest signal that testing AI applications is not optional.
Here is why testing AI applications matters:
- Accuracy is not guaranteed by design: AI systems predict based on patterns, not facts, and the same input can return different outputs.
- Bias can be invisible until it causes harm: Models trained on skewed data systematically disadvantage certain user groups without throwing an error.
- Regulatory exposure is real: GDPR, HIPAA, and the EU AI Act require demonstrable testing and auditability of AI-powered systems.
- Production behavior differs from test behavior: AI agents behave differently under real user load, diverse personas, and edge-case inputs.
- Trust, once lost, is hard to recover: One high-profile failure from an untested AI feature erodes user confidence well beyond the incident itself.
Note: Test AI applications at scale with purpose-built agent testing infrastructure. Try TestMu AI today.
How Is AI Testing Different From Traditional Testing?
Traditional software testing rests on a core assumption: given the same input, the system produces the same output. Deterministic behavior is the foundation that makes test automation tractable. You write assertions. You run tests. Pass or fail.
AI applications break that assumption entirely. The same prompt sent to an LLM can produce measurably different outputs depending on model temperature, context window state, and inference-time sampling. This introduces testing problems that traditional QA frameworks are not built to handle.
| Dimension | Traditional Software Testing | AI Application Testing |
|---|---|---|
| Output predictability | Same input always returns the same output | The same input can return different outputs across runs |
| Pass/fail logic | Binary: output matches the expected value, or it does not | Range-based: output falls within acceptable quality thresholds |
| Test flakiness | Flakiness indicates an infrastructure or code problem | Flakiness can be genuine behavioral variance, not a bug |
| Data dependency | Code behavior does not change when data changes | Model behavior shifts when training data or model version changes |
| Quality dimensions | Functional correctness, performance, security | Adds hallucination rate, bias, tone consistency, and fairness across personas |
| Ground truth | Defined expected output exists for every test case | No single correct answer exists for many AI outputs |
| Evaluation method | Automated assertions against exact values | Statistical scoring, LLM-as-judge, or human evaluation rubrics |
That change in mindset, from deterministic bug hunting to probabilistic quality evaluation, is the starting point for effective AI in QA practice.
What Are the Types of AI Application Testing?
AI application testing types include functional, performance, bias and fairness, robustness, regression, security, and compliance testing.
Testing AI applications requires a layered approach because failure modes exist at multiple levels of the system.
- Functional testing: Validates that the AI application produces outputs that are accurate and relevant to the input. For a chatbot, this means checking that responses address the actual user intent. For a classification model, it means verifying label accuracy against a held-out test set.
- Performance testing: AI systems require more rigorous load testing than traditional applications, since inference is resource-intensive and latency-sensitive. AI endpoints also show wider latency variability than standard APIs, which can cause client-side timeout issues.
- Bias and fairness testing: Evaluate whether the system treats all user groups equitably. This includes testing across demographic variables, languages, and edge-case personas such as non-native speakers, elderly users, and users with accessibility needs.
- Robustness testing: Deliberately probes the system with adversarial inputs, edge cases, and unexpected scenarios to understand failure boundaries. AI agents under adversarial testing often reveal failure patterns that would never surface in standard test cases.
- Regression testing: AI in regression testing is more complex than in traditional software, as changes in models, data pipelines, or infrastructure can subtly affect behavior. A/B testing between model versions is often used to identify these differences.
- Security testing: AI applications include prompt injection attacks, data exfiltration through model outputs, and adversarial manipulation of model behavior. These are attack surfaces that do not exist in traditional software.
- Compliance and governance testing: Verifies that the AI application meets regulatory requirements (HIPAA, GDPR, PCI DSS) and internal ethical policies. This is increasingly non-negotiable for enterprise deployments.
What to Test For in AI Applications?
Test for hallucination rate, context retention, tone consistency, task completion, latency, and escalation logic across AI-powered systems.
The specific quality attributes to test vary by application type, but some dimensions apply broadly to most AI-powered systems.
- Hallucination rate: Does the model generate factually incorrect or fabricated information? Rates vary widely by model, task type, and domain, and are highest in legal, medical, and financial contexts, exactly where AI is being deployed fastest.
- Context retention and conversation flow: In multi-turn conversations, does the agent maintain context correctly across the session? Does it forget prior instructions or contradict earlier statements?
- Tone and persona consistency: Does the agent maintain a consistent communication style across diverse users and scenarios?
- Task completion rate: For agent-based systems, does the agent actually resolve the user's problem, or does it loop, stall, or produce responses that sound helpful but accomplish nothing?
- Latency and reliability: Does the system respond within acceptable time bounds under realistic load conditions?
- Escalation and handoff logic: For agents connected to human support workflows, does escalation happen correctly when the agent reaches the boundary of its competence?
These dimensions collectively define the evaluation scope for agentic testing, validating not just whether the agent responds, but whether it reasons, remembers, and resolves correctly across every interaction.

What Factors Matter When Testing AI Applications?
Key factors include defining quality thresholds, building diverse test datasets, planning continuous testing, separating evaluation from automation, and documenting coverage.
Before running a single test, there are structural decisions that shape the entire testing program. When teams first attempt to test a multi-turn chatbot, the hardest part is rarely the tooling. It is agreeing on what counts as a failure.
- Define acceptable quality ranges: Unlike traditional testing, where pass/fail is binary, AI testing requires pre-agreed thresholds. What hallucination rate is acceptable for your use case? What bias differential across user groups is tolerable before the model is considered unfit for production?
- Build diverse test datasets: Testing an AI system on a narrow or homogeneous dataset will miss the failures that matter in production. Include edge cases, diverse personas, adversarial inputs, and domain-specific scenarios.
- Plan for continuous testing: AI systems evolve constantly. Changes like model updates, fine-tuning, retrieval index adjustments, and infrastructure shifts can all impact behavior. Testing isn't a one-time step before launch; it's an ongoing process aligned with the model lifecycle.
- Separate evaluation from automation: Some AI quality attributes (tone quality, response helpfulness, contextual appropriateness) require human judgment or specialized LLM-based evaluation, not just automated assertions. The testing architecture needs both.
- Document your test coverage: Because AI failure modes are numerous and not always obvious, systematic documentation of what is and is not being tested is essential for governance and auditability.
How to Test AI Applications?
Define intended behavior, build test datasets, establish evaluation criteria, run baseline tests, monitor production, test adversarial inputs, and document results.
The NIST AI Risk Management Framework (AI RMF), published by the National Institute of Standards and Technology, establishes Testing, Evaluation, Verification, and Validation (TEVV) as a core function across the entire AI lifecycle, not just a pre-launch gate.
Performed regularly, TEVV tasks provide insights relative to technical, societal, legal, and ethical standards, and assist with anticipating impacts and tracking emergent risks.
The framework further specifies that AI systems must be tested before deployment and monitored regularly during operation, with measurement methodologies following scientific, legal, and ethical norms.
The steps below reflect those principles in practice.
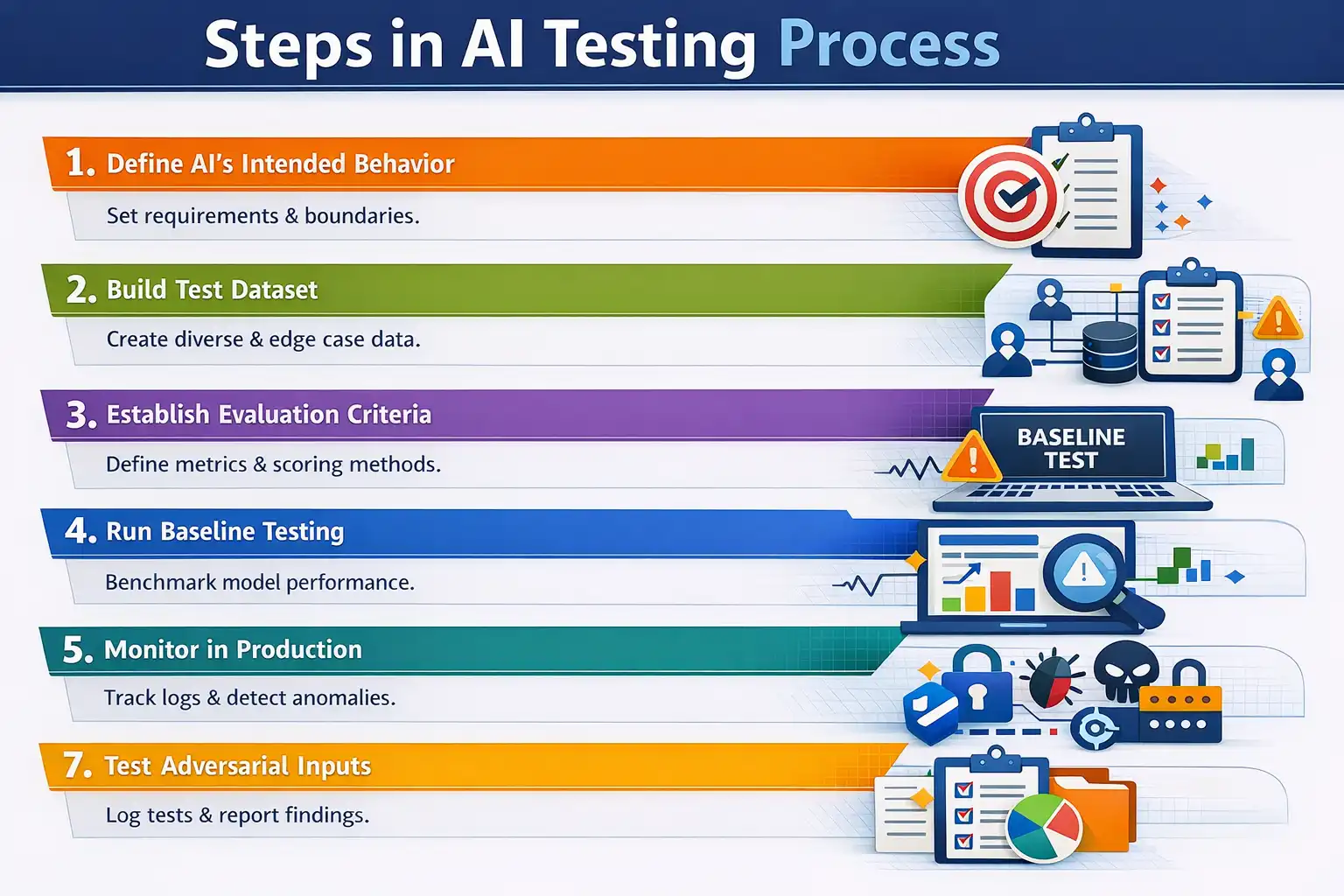
- Define the AI's intended behavior: Write clear specifications for what the application should and should not do. This includes functional requirements, quality thresholds, prohibited outputs, and escalation conditions. Without this, there is nothing to test against.
- Build a representative test dataset: Assemble test inputs that cover normal cases, edge cases, adversarial inputs, diverse user personas, and domain-specific scenarios. For conversational AI, include multi-turn conversation traces, not just single-turn exchanges.
- Establish evaluation criteria: For each quality dimension (accuracy, hallucination rate, bias, tone), define how you will score outputs. This may be automated metrics, LLM-as-judge scoring, human evaluation, or a combination.
- Run baseline testing before deployment: Establish a benchmark for the model's behavior across your test dataset before any production release. This baseline becomes the reference point for regression testing after every update.
- Implement continuous monitoring in production: Pre-deployment testing catches known failure modes. Production monitoring catches the ones you did not anticipate. Set up logging, anomaly detection, and sampling-based human review for live traffic.
- Test for adversarial inputs: Deliberately attempt to manipulate the AI system with prompt injections, jailbreak attempts, and edge-case inputs designed to expose unexpected behavior. This is especially critical for customer-facing AI agents.
- Document and track results: Maintain test run history, model version tags, evaluation scores, and identified failure patterns. This documentation is required for compliance audits and enables systematic improvement over time.
Intelligent test automation can accelerate many of these steps, particularly test generation, scenario coverage, and regression comparison. However, the judgment calls about what to test and what acceptable quality looks like still require human expertise.
The cost of skipping these steps is not theoretical. In 2023, attorneys in Mata v. Avianca, Inc. submitted legal filings to a New York federal court citing six cases generated by ChatGPT.
None of the cases existed. The court sanctioned the attorneys, and the incident became one of the most widely reported examples of what happens when AI output reaches a high-stakes context without any validation process behind it.
Following these steps manually is possible for small-scale deployments. But as AI agents handle thousands of conversations daily, across diverse personas, languages, and edge cases, manual testing coverage becomes inadequate.
That is where a full-stack Agentic AI Quality Engineering platform like TestMu AI(Formely LambdaTest) becomes necessary, one built to plan, author, execute, and analyze AI quality at scale.
How Does TestMu AI Enable Agentic AI Application Testing?
TestMu AI uses Agent-to-Agent Testing with 15+ specialized AI agents to autonomously generate, execute, and evaluate thousands of test scenarios in parallel.
TestMu AI empowers teams to test intelligently and ship faster. Engineered for scale, it offers end-to-end AI agents to plan, author, execute, and analyze software quality across web, mobile, and enterprise applications, on real devices, real browsers, and custom real-world environments.
Testing AI agents at scale requires purpose-built infrastructure. Manual scenario creation covers a fraction of the behavioral space that production AI systems navigate daily.
Agent-to-Agent Testing by TestMu AI is the world's first unified platform designed specifically to validate AI agents, including chatbots, voice assistants, and phone caller agents.
It uses 15+ specialized AI testing agents to autonomously generate, execute, and evaluate thousands of test scenarios in parallel, covering the behavioral space that manual testing cannot reach. Key capabilities include:
- Hallucination and bias detection: Automated evaluation for hallucinations, toxic content, bias, completeness, and context awareness across every scenario run.
- Diverse persona testing: 200+ voice profiles and 20+ background environments to simulate realistic user populations, including impatient users, multi-lingual callers, accessibility-needs users, and adversarial users.
- Multi-modal test generation: Upload requirements in any format (PDFs, JIRA tickets, audio, video, PRDs) and automatically generate comprehensive test scenarios from those inputs.
For teams building or automating test coverage for traditional web and mobile applications alongside AI features, KaneAI by TestMu AI enables test authoring through natural language prompts without requiring programming expertise, with export to Playwright, Selenium, Cypress, and Appium.
TestMu AI also offers Agent Skills: pre-built, reusable testing capabilities that QA agents can call to perform common validation tasks, reducing the overhead of building test infrastructure from scratch for agentic testing workflows.
To see how Agent-to-Agent Testing works in practice, TestMu AI provides a step-by-step walkthrough of testing your first AI agent, covering setup, scenario configuration, and evaluation output in a real deployment context.
What Are the Best AI Software Testing Tools?
Top AI testing tools include TestMu AI, DeepEval, Promptfoo, RAGAS, Langfuse, Arize Phoenix, and traditional frameworks like Selenium, Playwright, and Cypress.
Several AI testing tools are still maturing, but a growing number of evaluation frameworks and platforms now address different layers of testing AI applications reliably.
- TestMu AI (KaneAI + Agent-to-Agent Testing): An AI-native testing platform covering both traditional app testing and AI agent validation. KaneAI authors and runs test cases using natural language prompts with no coding required. Agent-to-Agent Testing validates chatbots, voice agents, and phone caller agents across hallucination, bias, tone, and task completion using 15+ specialized AI testing agents.
- DeepEval: An open-source Python-based LLM evaluation framework that treats evaluations as unit tests. Supports 60+ metrics across RAG, chatbot, and safety testing, with LLM-as-judge scoring and CI/CD integration.
- Promptfoo: An open-source toolkit for prompt testing, regression testing, and red teaming. Runs automated security scans for prompt injections, jailbreaks, and data leakage with no cloud setup required.
- RAGAS: An open-source evaluation framework built specifically for RAG pipelines. Measures faithfulness, answer relevancy, and context precision across retrieval and generation steps.
- Langfuse: An open-source LLM engineering platform covering tracing, prompt management, evaluation, and production monitoring in a single system. Preferred by teams with data residency requirements.
- Arize Phoenix: An open-source observability platform built on OpenTelemetry. Captures multi-step agent traces, supports hallucination and quality evaluations, and integrates with LangChain, LlamaIndex, and most major LLM frameworks.
- Selenium / Playwright / Cypress: Traditional automation frameworks that remain relevant for testing the UI and functional layers of AI-powered applications, even when the AI backend requires specialized evaluation tooling.

What Are the Challenges in Testing AI Applications?
Key challenges include non-deterministic outputs, hallucination detection at scale, lack of standardised metrics, scenario coverage gaps, and undetected production drift.
Testing AI applications is harder than testing traditional software. Here are the core challenges QA teams face and what current research and tooling say about solving them.
Challenge 1: Non-determinism makes tests unreliable
The same prompt, sent twice, can return different outputs. According to a 2025 taxonomy paper published on arXiv, subtle prompt variations can invert model responses even under high-confidence settings, and repeated queries, despite deterministic configurations such as temperature set to zero, can still produce inconsistent outputs. Traditional pass/fail assertions break entirely in this environment.
Solution: Shift from single-run assertions to statistical evaluation. Run each test scenario multiple times and evaluate aggregate pass rates against pre-defined thresholds. Property-based testing, where you define properties that must hold across all outputs rather than testing exact values, is an established approach for non-deterministic systems.
Challenge 2: Hallucinations are hard to detect at scale
AI models generate factually incorrect outputs with the same fluency and confidence as correct ones. Manual review cannot scale to production traffic volumes.
Solution: Retrieval-Augmented Generation (RAG) is currently the most evidence-backed mitigation. A peer-reviewed study from the National Cancer Center Japan, published in PubMed in September 2025, found that RAG-based chatbots using reliable domain-specific sources achieved 0% hallucination rates for GPT-4, compared to approximately 40% for conventional chatbots without RAG.
For teams that cannot implement RAG, automated hallucination detection frameworks such as DeepEval and RAGAS provide scalable evaluation at the pipeline level.
Challenge 3: No standardised metrics for AI quality
Unlike traditional software, AI agents require evaluation across hallucination rate, bias, tone consistency, context awareness, and fairness. None of these have universally accepted measurement standards, which makes benchmarking and governance difficult.
Solution: The NIST AI Risk Management Framework provides the most authoritative guidance available. It specifies that measurement methodologies for AI systems should follow scientific, legal, and ethical norms, with scalable and adaptable methods developed as AI risks evolve.
Teams should define their own quality rubrics against NIST's trustworthiness characteristics: validity, reliability, safety, security, explainability, and fairness.
Challenge 4: Scale of scenario coverage
AI agents can produce effectively infinite response variations. A customer service bot handling 10,000 daily conversations navigates a behavioral space that no manual test suite can meaningfully cover.
Solution: Automated multi-agent test generation addresses this directly. Rather than hand-crafting scenarios, purpose-built platforms autonomously generate thousands of test cases across diverse personas, edge cases, and adversarial inputs. This is the gap that agentic testing infrastructure, including TestMu AI's Agent-to-Agent Testing, is built to close.
Challenge 5: Production drift goes undetected
A model that passes all pre-deployment tests can degrade silently in production as real user inputs diverge from test data, model versions change, or retrieval indexes are updated.
Solution: The NIST AI RMF specifies that AI systems must be monitored regularly during operation, not just tested before deployment. In practice, this means implementing logging on live traffic, sampling-based human review, and anomaly detection that flags output distributions shifting away from baseline behavior. Production monitoring is not optional; it is the second half of any complete testing program.
Best Practices to Test AI Applications Effectively
A few principles separate teams that make consistent progress from those that stay stuck.
- Test behavior, not just outputs: For AI agents, a response that is technically accurate but tonally inappropriate or contextually wrong is still a failure. Define behavioral expectations broadly enough to catch the failures that matter to users.
- Use statistical testing for non-deterministic systems: AI test automation cannot rely on single-run assertions for probabilistic systems. Run each test scenario multiple times and evaluate aggregate pass rates, not just individual runs. A hallucination that occurs in 15% of runs on a given prompt is a real production risk even if most individual test runs pass.
- Build production feedback loops: The most valuable testing signal comes from real user interactions. Sampling and reviewing production conversations, flagging anomalies, and feeding failure patterns back into your test dataset closes the gap between lab conditions and real-world performance.
- Involve domain experts in evaluation: Automated metrics catch a lot, but domain-specific quality issues (medical accuracy, legal precision, financial compliance) require human reviewers with subject matter expertise. Build this into your QA process from the start, not as an afterthought.
- Version your tests alongside your model: When a model is updated, re-run the full test suite and track score deltas against the previous version. Regression in any quality dimension should be a hard gate before promotion to production.
- Treat agentic testing as a first-class capability: As AI systems move from single-turn completions to multi-step autonomous agents, AI agent use cases now span customer service, legal research, financial advisory, and healthcare triage. Testing must evolve to cover agent planning, tool use, multi-agent coordination, and failure recovery across all of these contexts. Agentic software testing requires deliberate investment in both tooling and team expertise.
The organizations that do this well are not necessarily the ones with the biggest teams or the most sophisticated tooling. They are the ones who treat AI quality as an ongoing operational discipline rather than a pre-launch checklist.
Conclusion
Testing AI applications is not a problem that goes away as AI models improve. If anything, it becomes more pressing as AI takes on higher-stakes roles across healthcare, finance, customer service, and enterprise operations.
The core shift required is not technical. It is a change in how QA teams think about quality. Deterministic pass/fail logic is not enough when the system you are testing predicts rather than computes. Statistical evaluation, behavioral rubrics, continuous production monitoring, and purpose-built AI testing infrastructure are not optional enhancements. They are the baseline for shipping AI responsibly.
The teams that build this discipline now, before a production failure forces the issue, are the ones that will ship AI-powered products with genuine confidence. The ones that treat testing as a pre-launch checkbox will keep discovering that AI quality problems do not stay in the lab.
Citations
- The State of AI: Global Survey 2025 | McKinsey
- The State of AI in the Enterprise - 2026 AI report | Deloitte Global
- Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile
- Challenges in Testing Large Language Model Based Software: A Faceted Taxonomy
- Judge sanctions lawyers for brief written by A.I. with fake citations
Frequently asked questions
Did you find this page helpful?
More Related Hubs
TestMu AI forEnterprise
Get access to solutions built on Enterprise
grade security, privacy, & compliance
- Advanced access controls
- Advanced data retention rules
- Advanced Local Testing
- Premium Support options
- Early access to beta features
- Private Slack Channel
- Unlimited Manual Accessibility DevTools Tests